大数据培训_Hbase为什么容量大速度快
引言Hbase被誉为超级大型分布式的数据库,适合于存储大表数据(表的规模可以达到数十亿行以及数百万列),并且对大表数据的读、写访问可以达到实时级别。为什么Hbase可以存储那么大量的数据呢,为什么Hbase这么大型的数据可以实时读取。
Hbase介绍Hbase是一个面向列、可伸缩、高可靠性、高性能的分布式存储系统,同时也叫做分布式的数据库。利用Hbase技术可在廉价PC Server上搭建起大规模结构化存储集群。Hbase的目标是存储并处理大型的数据,更具体来说是仅需使用普通的硬件配置,就能够处理由成千上万的行和列所组成的大型数据。
Hbase 架构

Habse写数据流程① 客户端发起请求
② 通过ZooKeeper寻找到meta表所在RegionServer
③ meta表中记载着各个User Region信息(rowkey范围,所在RegionServer),通过meta表寻找所要写入的Region所在RegionServer
④ 请求按RegionServer和Region打包发送到Region所在RegionServer,由该RegionServer具体处理数据写入
habse读数据流程① 客户端发起请求
② 通过ZooKeeper寻找到meta表所在RegionServer
③ meta表中记载着各个User Region信息(rowkey范围,所在RegionServer),通过rowkey查找meta表,获取所要读取的Region所在RegionServer
④ 请求发送到该RegionServer,由其具体处理数据读取
⑤ 数据读取返回到客户端
为什么Hbase可以存储那么大量的数据呢利用Hadoop HDFS(Hadoop Distributed File System)作为其文件存储系统,提供实时读写的分布式数据库系统。
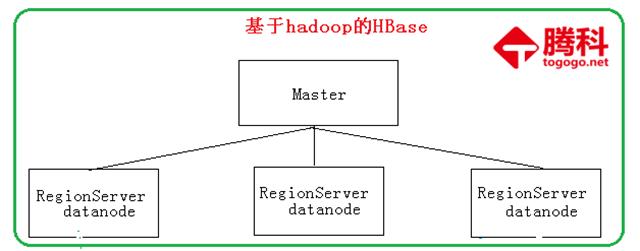
从上图了解到,如果你掌握了hadoop中的hdfs分布式文件系统,就很容易理解hbase为什么能存储大量的数据。Hbase本身就是利用hadoop中的hdfs作为它的存储系统。
为什么Hbase这么大型的数据可以实时读取
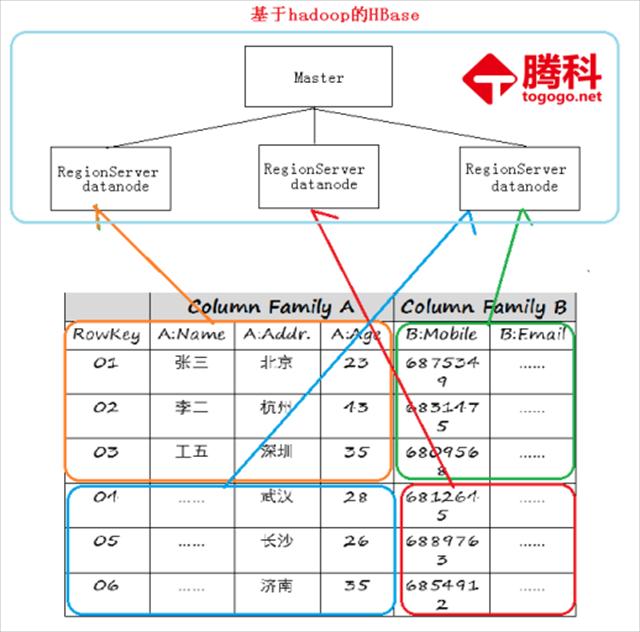
很明显habse是把一个超级大的表,进行分割成一块一块的数据,然而这一块一块都会带着rowkey,把这一块一块的数据存储到hadoop中的datanode数据节点中,这样我们就保证大数表的数据被分成一个一个很小的表,从而数据库要读一个小表,那是多么简单的事情,所以超级大表实现秒级也是可能的。




